AI 기술의 발전으로 ChatGPT, Claude와 같은 강력한 언어 모델이 개발 환경에 통합되고 있습니다. 그러나 이러한 모델들은 최신 정보나 특정 도메인(예: 네이버 검색 결과)에 대한 실시간 접근성에 제한이 있습니다. MCP(Model Context Protocol)는 이러한 한계를 극복하기 위한 표준화된 프로토콜로, AI 모델이 외부 도구 및 데이터 소스와 안전하고 효율적으로 상호작용할 수 있도록 지원합니다.
이 글을 통해 Python과 MCP를 활용하여 네이버 검색 기능을 AI 에이전트에 통합하는 실질적인 방법을 학습합니다.
Github : https://github.com/jikime/py-mcp-naver-search
Smithery: https://smithery.ai/server/@jikime/py-mcp-naver-search
제1장: 준비 및 환경 설정
본격적인 MCP 서버 개발에 앞서, 필요한 사전 준비 작업과 개발 환경을 구성합니다. 네이버 Open API 사용을 위한 인증 키를 발급받고, uv를 사용하여 macOS 환경에 Python 프로젝트 및 가상 환경을 설정하는 과정을 다룹니다.
1.1 네이버 Open API 키 발급
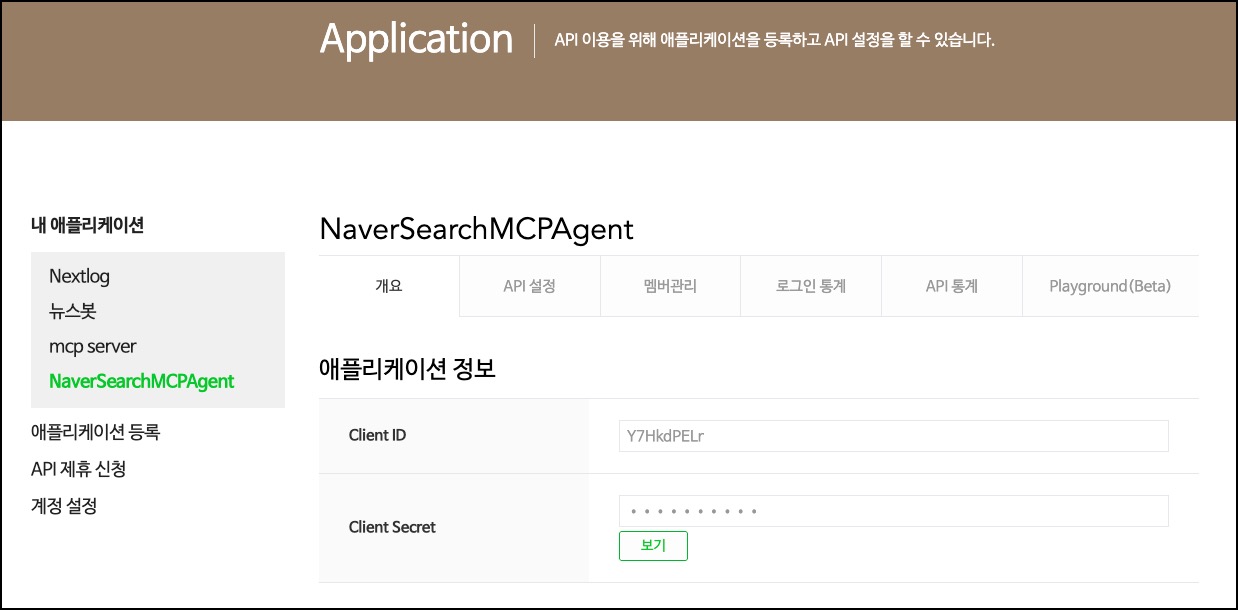
네이버 검색 API를 활용하기 위해서는 먼저 네이버 개발자 센터를 통해 API 이용 권한을 신청하고 인증 정보를 발급받아야 합니다. 이 인증 정보는 클라이언트 ID(Client ID)와 와 클라이언트 시크릿(Client Secret)으로 구성되며, API 호출 시 클라이언트를 식별하고 인증하는 데 사용됩니다.
API 키 발급 절차
네이버 개발자 센터 접속 및 로그인
웹 브라우저를 통해 NAVER Developers 사이트에 접속하고 네이버 계정으로 로그인합니다.
애플리케이션 등록
상단 메뉴에서 Application > 애플리케이션 등록을 선택합니다. 애플리케이션 등록 양식에 다음 정보를 입력합니다.
- 애플리케이션 이름: 프로젝트를 식별할 수 있는 명확한 이름을 지정합니다 (예: NaverSearchMCPAgent).
- 사용 API: 제공되는 API 목록 중 '검색' API를 선택합니다. 필요에 따라 다른 API를 추가로 선택할 수 있습니다.
- 환경 추가: API를 사용할 환경을 설정합니다. 로컬 개발 및 테스트 목적이므로 WEB 설정을 선택하고 서비스 URL로 http://localhost를 등록합니다. 실제 서비스 배포 시에는 해당 서비스의 URL로 변경해야 합니다.
등록 완료 및 인증 정보 확인
등록 절차를 완료하면 Client ID와 Client Secret 값이 화면에 표시됩니다. 이 두 값은 민감 정보에 해당하므로 안전하게 별도로 기록해 두어야 합니다. 이후 프로젝트 설정 단계에서. env 파일에 이 값을 저장하게 됩니다.

팁: Client ID와 Secret은 외부에 노출되지 않도록 각별히 주의해야 합니다. Git 저장소 등에 직접 커밋하지 않도록 관리하는 것이 중요합니다.
1.2 프로젝트 설정 및 가상 환경 구성 (uv 사용, macOS)
Python 프로젝트는 독립적인 라이브러리 환경을 위해 가상 환경 내에서 개발하는 것이 권장됩니다. 이를 통해 시스템 전체 Python 환경과의 충돌을 방지하고 프로젝트 의존성을 명확하게 관리할 수 있습니다. 여기서는 최신 Python 패키지 관리 도구인 uv를 사용하여 프로젝트 설정 및 가상 환경 구성을 진행합니다.
uv 설치
uv는 기존 pip 및 venv의 기능을 통합하고 빠른 속도를 제공하는 도구입니다. macOS 환경에서는 다음 두 가지 방법으로 설치할 수 있습니다.
방법 1: Homebrew 사용 (권장)
macOS 사용자의 경우 Homebrew를 이용하는 것이 가장 간편합니다. Homebrew가 설치되어 있지 않다면 Homebrew 공식 사이트를 참조하여 먼저 설치하십시오.
Homebrew 설치 확인
터미널에서 brew --version 명령을 실행하여 Homebrew 설치 여부를 확인합니다.
uv 설치
터미널에서 다음 명령을 실행하여 uv를 설치합니다.
brew install uv
방법 2: 공식 설치 스크립트 사용 (Global 설치)
Homebrew를 사용하지 않거나 시스템 전역에 uv를 직접 설치하고 싶은 경우, 공식 설치 스크립트를 사용할 수 있습니다.
설치 스크립트 실행
터미널에서 다음 명령을 실행합니다. 이 스크립트는 uv 바이너리를 다운로드하여 시스템 경로에 설치합니다.
curl -LsSf https://astral.sh/uv/install.sh | sh
주의: 인터넷에서 다운로드한 스크립트를 sh로 바로 실행하는 것은 보안 위험을 내포할 수 있습니다. 스크립트 내용을 먼저 확인하고 실행하는 것이 안전합니다.
설치 확인
두 방법 중 하나로 설치를 완료한 후, 터미널에서 uv --version 명령을 실행하여 설치된 uv 버전을 확인합니다.
프로젝트 디렉터리 및 가상 환경 생성
프로젝트 생성
터미널을 사용하여 프로젝트를 저장할 상위 디렉터리로 이동합니다. 새로운 프로젝트를 생성하고 초기 파일을 설정하기 위해 다음 명령어를 사용합니다. (python 3.12 버전을 사용합니다.)
uv init py-mcp-naver-search -p 3.12생성된 디렉터리 내에 pyproject.toml 파일과 몇 가지 필수 파일이 자동으로 생성됩니다.
가상 환경 생성
현재 디렉터리(py-mcp-naver-search)에서 uv venv 명령을 실행하여 가상 환경을 생성합니다. 가상 환경 디렉터리 이름은. venv를 사용합니다.
uv venv
명령 실행 후 현재 디렉터리에. venv 폴더가 생성되었는지 확인합니다.
가상 환경 활성화
생성된 가상 환경을 사용하기 위해서는 활성화 과정이 필요합니다. 활성화하면 해당 터미널 세션에서는 시스템 Python이 아닌 가상 환경의 Python 인터프리터와 라이브러리를 사용하게 됩니다. 터미널에서 다음 명령을 실행하여 가상 환경을 활성화합니다.
source .venv/bin/activate
가상 환경이 성공적으로 활성화되면, 터미널 프롬프트 시작 부분에 (py-mcp-naver-search)와 같은 표시자가 나타납니다. 가상 환경 사용을 종료하려면 deactivate 명령을 실행합니다.

필요 라이브러리 설치
가상 환경이 활성화된 상태에서 프로젝트에 필요한 Python 라이브러리들을 설치합니다. uv add 명령을 사용합니다.
uv add "mcp[cli]" httpx pydantic python-dotenv- mcp [cli]: MCP 서버 및 클라이언트 개발을 위한 공식 Python SDK입니다. 서버 구현을 위한 FastMCP 프레임워크를 포함합니다.
- httpx: 네이버 API와 같은 외부 HTTP 서비스와 통신하기 위한 비동기 HTTP 클라이언트 라이브러리입니다. requests 라이브러리와 유사하지만 비동기 프로그래밍을 지원합니다.
- pydantic: 타입 어노테이션을 기반으로 데이터 유효성 검사 및 설정을 관리하는 라이브러리입니다. API 응답 데이터의 구조를 정의하고 검증하는 데 유용합니다.
- python-dotenv:. env 파일에 정의된 환경 변수를 로드하여 애플리케이션에서 사용할 수 있게 해주는 라이브러리입니다.

인증 정보 관리 (. env 파일 생성)
네이버 API Client ID 및 Secret과 같은 민감 정보를 소스 코드에 직접 작성하는 대신,. env 파일을 사용하여 관리하는 것이 안전합니다.
.env 파일 생성
프로젝트 루트 디렉터리(py-mcp-naver-search)에. env 파일을 생성하고, 1.1 단계에서 발급받은 네이버 API 키를 다음 형식으로 저장합니다.
NAVER_CLIENT_ID=여기에_발급받은_Client_ID_입력
NAVER_CLIENT_SECRET=여기에_발급받은_Client_Secret_입력
. gitignore 설정
. env 파일은 민감 정보를 포함하므로 Git 버전 관리 대상에서 제외해야 합니다. 프로젝트 루트 디렉터리에. gitignore 파일을 생성하고 다음 내용을 추가합니다.
# .gitignore
# 가상 환경 디렉토리
.venv/
# 환경 변수 파일
.env
# Python 캐시 파일
__pycache__/
*.pyc
# 기타 프로젝트별 제외 파일 추가 가능
최종 프로젝트 구조
지금까지의 설정을 완료하면 프로젝트 디렉터리(py-mcp-naver-search)는 다음과 같은 기본 구조를 갖게 됩니다.
py-mcp-naver-search/
├── .venv/ # Python 가상 환경 디렉토리
├── .env # 네이버 API 키 저장 파일 (Git 무시됨)
├── .gitignore # Git 무시 파일 목록
└── server.py # MCP 서버 코드 (이후 생성)
└── client.py # MCP 클라이언트 코드 (이후 생성)
이 구조를 바탕으로 이후 단계에서 server.py와 client.py 파일을 생성하고 코드를 작성하게 됩니다.
제2장: 네이버 검색 API 및 MCP 서버 설계
MCP 서버 구축에 앞서, 활용할 네이버 검색 Open API의 종류와 특징을 파악하고, 이를 기반으로 MCP 서버의 구조를 설계합니다. Pydantic 모델을 사용하여 API 응답 데이터 구조를 정의하는 방법을 포함합니다.
2.1 네이버 검색 Open API 개요
네이버 검색 Open API는 네이버의 방대한 검색 결과를 외부 애플리케이션에서 활용할 수 있도록 RESTful API 형태로 제공합니다. 총 13개의 엔드포인트를 통해 뉴스, 블로그, 쇼핑, 이미지 등 특정 분야의 정보를 조회할 수 있습니다.
API 기본 정보
- 요청 방식: 모든 검색 API는 HTTP GET 메서드를 사용합니다.
- 응답 형식: 기본적으로 JSON 형식을 지원하며, 요청 URL의 엔드포인트 뒤에. json 또는. xml 확장자를 붙여 명시적으로 선택할 수 있습니다. 이 글에서는 JSON 형식을 사용합니다.
- 인증 방식: HTTP 요청 헤더에 X-Naver-Client-Id와 X-Naver-Client-Secret 값을 포함하여 인증합니다. (1.1 단계에서 발급받은 키 사용)
제공 엔드포인트 (13종)
다음은 네이버 검색 API가 제공하는 13가지 주요 엔드포인트와 간략한 설명입니다. 자세한 사항은 네이버 검색 API 문서에서 확인할 수 있습니다.
- /v1/search/blog.json: 네이버 블로그 검색 결과
- /v1/search/news.json: 네이버 뉴스 검색 결과
- /v1/search/book.json: 네이버 책 검색 결과
- /v1/search/adult.json: 검색어의 성인 검색어 판별 결과 (결과 구조 다름)
- /v1/search/encyc.json: 네이버 지식백과 검색 결과
- /v1/search/cafearticle.json: 네이버 카페 게시글 검색 결과
- /v1/search/kin.json: 네이버 지식iN Q&A 검색 결과
- /v1/search/local.json: 네이버 지역(플레이스) 검색 결과
- /v1/search/errata.json: 한영 오타 변환 결과 (결과 구조 다름)
- /v1/search/shop.json: 네이버 쇼핑 상품 검색 결과
- /v1/search/doc.json: 전문자료(학술 정보) 검색 결과
- /v1/search/image.json: 네이버 이미지 검색 결과
- /v1/search/webkr.json: 웹 문서 검색 결과
주요 요청 파라미터
API 호출 시 URL 쿼리 스트링으로 전달하는 주요 파라미터는 다음과 같습니다.
- query (string, 필수): 검색할 키워드를 UTF-8로 인코딩하여 전달합니다.
- display (integer, 선택): 한 번의 API 호출로 반환받을 검색 결과의 개수를 지정합니다. (기본값: 10, 최댓값: 100)
- start (integer, 선택): 검색 결과의 시작 위치를 지정합니다. (기본값: 1, 최댓값: 1000). display 값과 조합하여 페이지네이션 구현에 사용됩니다. 1000 이후의 결과는 API를 통해 조회할 수 없습니다.
- sort (string, 선택, 일부 API): 검색 결과의 정렬 방식을 지정합니다. (예: sim - 정확도순, date - 최신순). 사용 가능한 옵션은 API 종류별로 다릅니다.
응답 구조 예시 (블로그 검색)
대부분의 검색 API는 유사한 JSON 구조로 응답합니다. 다음은 블로그 검색 결과의 예시입니다.
{
"lastBuildDate": "Tue, 29 Apr 2025 11:20:00 +0900", // 결과 생성 시각
"total": 123456, // 해당 검색어의 총 결과 수
"start": 1, // 현재 결과의 시작 위치
"display": 10, // 요청한 결과 표시 개수
"items": [ // 실제 검색 결과 항목 배열
{
"title": "<b>MCP</b> 서버 개발 후기", // HTML 태그 포함될 수 있음
"link": "https://blog.naver.com/...", // 원문 링크
"description": "Python FastMCP를 이용한 <b>MCP</b> 서버 구축 과정...", // 요약 내용
"bloggername": "개발자의 블로그", // 블로거 이름
"bloggerlink": "https://blog.naver.com/...", // 블로그 주소
"postdate": "20250428" // 포스팅 날짜 (YYYYMMDD)
},
// ... (display 개수만큼의 항목)
]
}
items 배열 내의 필드는 API 종류에 따라 다릅니다. adult, errata API는 이와 다른 단일 결과 구조를 가집니다.
쿼터 및 제한 사항
- 일일 호출량: 무료 사용자는 하루 최대 25,000회까지 API를 호출할 수 있습니다. 쿼터는 매일 자정에 초기화됩니다.
- 결과 제한: 한 번의 요청으로 최대 100개의 결과를 받을 수 있으며(display=100), start 파라미터를 이용해도 최대 1000번째 결과까지만 접근 가능합니다. 즉, 1000개를 초과하는 결과는 API로 조회할 수 없습니다.
2.2 MCP 서버 구조 설계 및 Pydantic 모델 정의
네이버 검색 API의 특징을 바탕으로 MCP 서버의 구성 요소를 설계합니다. 각 API 엔드포인트는 MCP Tool로 매핑하고, 서버의 기능을 설명하는 정적 정보는 Resource로, AI에게 전달할 가이드라인은 Prompt로 구현합니다.
Pydantic 모델 정의
API 응답 데이터의 구조를 명확히 하고 유효성을 검증하기 위해 Pydantic 모델을 사용합니다. 각 API 응답의 items 필드 구조에 맞춰 개별 Item 모델(BlogItem, NewsItem 등)을 정의하고, 전체 응답 구조를 위한 SearchResultBase 모델과 이를 상속받는 각 API별 결과 모델(BlogResult, NewsResult 등)을 정의합니다.
- BaseItem: 모든 검색 결과 항목의 공통 필드(예: title, link)를 정의합니다. Optional 타입을 사용하여 필수가 아닌 필드를 표시합니다.
- 개별 Item 모델: BaseItem 또는 다른 Item 모델을 상속받아 각 API별 고유 필드를 추가합니다. (예: BlogItem은 bloggername, postdate 등 추가)
- SearchResultBase: total, start, display, items 등 공통 응답 구조를 정의합니다. items는 List [Any]로 정의하고, 실제 타입은 하위 모델에서 구체화합니다.
- 개별 Result 모델: SearchResultBase를 상속받아 items 필드의 타입을 해당 API의 Item 모델 리스트로 명시합니다. (예: BlogResult의 items는 List [BlogItem])
- 단일 결과 모델: AdultResult, ErrataResult와 같이 고유한 구조를 가진 API를 위한 별도 모델을 정의합니다.
- ErrorResponse 모델: API 호출 실패 또는 내부 오류 발생 시 클라이언트에게 구조화된 오류 정보를 전달하기 위한 모델을 정의합니다.
참고: Pydantic 모델을 사용하면 API 응답 JSON을 파싱 할 때 자동으로 데이터 타입 검증 및 변환이 이루어지며, 형식이 맞지 않을 경우 ValidationError가 발생하여 오류를 조기에 감지할 수 있습니다. Config 클래스의 extra = "ignore" 설정은 모델에 정의되지 않은 필드가 API 응답에 포함되어도 오류 없이 무시하도록 합니다.
제3장: MCP 서버 구현
Python과 FastMCP, httpx, Pydantic 등을 사용하여 MCP 서버의 핵심 로직을 구현합니다. 동적 Prompt, 페이지네이션, 로깅, 오류 처리 기능이 포함됩니다.
3.1 서버 코드 작성 (server.py)
프로젝트 디렉터리(py-mcp-naver-search) 내에 server.py 파일을 생성하고 다음 구성 요소들을 포함하여 코드를 작성합니다.
- 초기 설정: 필요한 라이브러리 임포트, logging 기본 설정, load_dotenv()를 이용한. env 파일 로드, FastMCP 서버 인스턴스 생성, 네이버 API 인증 헤더 설정 등을 수행합니다.
- Pydantic 모델 정의: 2.2 단계에서 설계한 Pydantic 모델들을 코드로 구현합니다.
- MCP Resource 구현: @mcp. resource() 데코레이터를 사용하여 get_available_search_categories 함수를 정의합니다. 이 함수는 서버가 제공하는 검색 카테고리 목록을 반환합니다.
- API 호출 공통 함수 (_make_api_call):
- httpx.AsyncClient를 사용하여 네이버 API를 비동기적으로 호출합니다.
- 성공 시 응답 JSON을 입력받은 result_model로 파싱 합니다.
- 파싱 된 결과(예: total, start, items 개수)를 기반으로 동적 Prompt 문자열을 생성합니다.
- 결과 딕셔너리와 Prompt 문자열을 튜플 형태로 반환합니다.
- try... except 블록을 사용하여 httpx.HTTPStatusError, httpx.RequestError, ValidationError 등 다양한 예외 상황을 처리합니다.
- 오류 발생 시 logging 모듈을 사용하여 상세 오류 정보를 기록하고, 구조화된 ErrorResponse 모델과 함께 "오류 발생:" Prompt를 반환합니다.
- 페이지 계산 함수 (calculate_start): page와 display 파라미터를 받아 네이버 API의 start 파라미터 값을 계산하는 헬퍼 함수를 정의합니다. API의 start 최댓값(1000) 제한을 고려합니다.
- MCP Tool 구현 (13종):
- 각 네이버 검색 API 엔드포인트에 대응하는 비동기 함수를 @mcp. tool() 데코레이터와 함께 정의합니다.
- 함수 시그니처에 query, display, page, sort, filter 등 필요한 파라미터를 타입 힌트와 함께 명시합니다. page 파라미터를 추가하여 페이지네이션을 지원합니다. (단, local, adult, errata 등 일부 API는 페이지네이션 미지원)
- 함수 내에서는 calculate_start 함수를 호출하여 start 값을 계산하고, _make_api_call 함수를 호출하여 실제 API 통신 및 결과 처리를 위임합니다.
- 각 Tool 함수는 _make_api_call로부터 받은 (결과 딕셔너리, Prompt 문자열) 튜플을 그대로 반환합니다.
- 서버 실행 안내: if __name__ == "__main__": 블록 내에 mcp dev server.py 명령을 사용하여 서버를 실행하도록 안내하는 메시지를 로거를 통해 출력합니다.
관련 소스는 github의 server.py 에서 확인 가능합니다.
3.2 MCP Inspector를 이용한 서버 테스트
구현된 서버 코드가 예상대로 동작하는지 검증하기 위해 MCP Inspector를 활용합니다.
서버 실행
가상 환경이 활성화된 터미널에서 프로젝트 루트 디렉터리로 이동한 후 다음 명령을 실행합니다.
mcp dev server.py터미널에 서버 시작 로그와 함께 Inspector 접속 주소가 표시됩니다.

Resource 테스트
Inspector 인터페이스에서 'Resources' 섹션을 찾아 get_available_search_categories를 실행하고, 반환되는 카테고리 목록이 올바른지 확인합니다.
Tool 테스트
'Tools' 섹션에서 search_blog와 같은 Tool을 선택하고, query 파라미터에 검색어를 입력한 후 실행합니다. 반환되는 JSON 결과와 하단의 'Prompt' 섹션에 동적으로 생성된 프롬프트(예: "네이버 블로그 검색 결과 (총 OOO건 중 O~O번째):")가 표시되는지 확인합니다.

제4장: MCP 클라이언트 구현 및 테스트
MCP 서버와의 상호작용을 프로그래밍 방식으로 테스트하기 위해 간단한 Python 클라이언트를 구현합니다. 이 클라이언트는 서버의 페이지네이션 파라미터를 지원하고, 동적 Prompt 및 구조화된 오류 응답을 처리할 수 있어야 합니다.
4.1 클라이언트 코드 작성 (client.py)
프로젝트 디렉터리에 client.py 파일을 생성하고 다음 로직을 포함하여 코드를 작성합니다.
- 라이브러리 임포트: asyncio, sys, json, mcp 관련 모듈을 임포트 합니다.
- 비동기 함수 정의 (run_search):
- 카테고리, 검색어 및 추가 파라미터(**kwargs)를 인자로 받습니다.
- StdioServerParameters를 사용하여 로컬 server.py 실행 설정을 정의합니다.
- stdio_client와 ClientSession콘텍스트를 사용하여 서버 프로세스를 시작하고 MCP 세션을 엽니다.
- session.initialize()를 호출하여 서버와 초기 통신을 수행합니다.
- 입력받은 카테고리와 kwargs를 기반으로 호출할 tool_name과 arguments 딕셔너리를 구성합니다.
- session.call_tool()을 호출하여 서버의 Tool을 실행하고 반환값을 받습니다.
- 반환된 결과 데이터 result 가 content 키가 있는지 확인하고, 정상 결과 또는 오류 정보를 텍스트 형식으로 출력합니다.
- try... except 블록으로 클라이언트 측 또는 서버에서 전달된 예외를 처리하고 오류 메시지를 출력합니다.
- 메인 실행 블록 (if __name__ == "__main__":):
- sys.argv를 사용하여 터미널 명령줄 인자를 파싱 합니다. 카테고리, 검색어, 그리고 key=value 형태의 추가 파라미터를 받도록 구현합니다. 숫자형 파라미터는 int로 변환합니다.
- 파싱 된 인자를 사용하여 asyncio.run(run_search(...))를 호출하여 클라이언트를 실행합니다.
관련 소스는 github의 client.py 에서 확인 가능합니다.
4.2 클라이언트 실행 테스트
가상 환경이 활성화된 터미널에서 client.py를 실행하여 서버 기능을 테스트합니다.
- 기본 검색:
uv run client.py book "파이썬 프로그래밍" display=5 page=1
- 페이지네이션 테스트:
uv run client.py blog "머신러닝" page=3 display=15- 정렬 옵션 테스트:
uv run client.py news "반도체 시장" sort=date page=1 display=5- 필터 옵션 테스트 (이미지):
uv run client.py image "겨울 바다" filter=large display=10- 페이지네이션 미지원 API 테스트:
uv run client.py local "강남역 맛집" display=5 sort=comment- 단일 결과 API 테스트:
uv run client.py errata "anfgo"

각 명령 실행 후 터미널에 출력되는 검색 결과 데이터와 동적 Prompt 내용을 확인합니다. 서버 측 로그도 함께 모니터링하여 요청 처리 과정을 추적할 수 있습니다.
제5장: AI 개발 환경 연동
개발 및 테스트가 완료된 MCP 서버를 실제 AI 어시스턴트가 통합된 개발 환경(Cursor IDE, Claude Desktop 등)에 연동하여 활용하는 방법을 설명합니다.
5.1 Cursor IDE 연동 설정
Cursor IDE는 MCP 서버를 로컬에서 실행하고 AI 기능과 연동하는 기능을 내장하고 있습니다.
Cursor 설치 및 기본 설정
Cursor IDE를 설치하고 OpenAI API 키 등 기본 설정을 완료합니다.
mcp.json 설정
사용자 홈 디렉터리 아래. cursor 폴더에 mcp.json 파일을 생성하거나 기존 파일을 엽니다. (예: /Users/사용자명/. cursor/mcp.json)
서버 정보 추가
mcpServers 객체 내에 새로운 서버 항목을 추가합니다. command는 uv의 절대경로를 사용합니다.
{
"mcpServers": {
"korea-weather": {
"command": "/Users/jikime/.local/bin/uv",
"args": [
"--directory",
"/Users/jikime/src/cookai.dev/oh-my-agent/mcp-servers/py-mcp-ko-weather",
"run",
"src/server.py"
],
"transport": "stdio"
},
"naver-search": {
"command": "/Users/jikime/.local/bin/uv",
"args": [
"--directory",
"/Users/jikime/src/cookai.dev/oh-my-agent/mcp-servers/py-mcp-naver-search",
"run",
"server.py"
],
"transport": "stdio"
}
}
}
Cursor 재시작 및 활성화
mcp.json 파일을 저장한 후 Cursor IDE를 재시작합니다. 우측 상단의 설정(톱니바퀴 아이콘) 메뉴 > MCP 항목으로 이동하여 방금 추가한 "naver-search" 서버를 찾아 스위치를 켜서 활성화(Enabled)합니다.

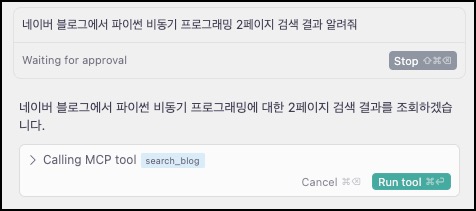
이제 Cursor의 AI 채팅 기능(CMD + L)에서 네이버 검색 관련 자연어 요청을 할 수 있습니다. 예를 들어, "네이버 블로그에서 파이썬 비동기 프로그래밍 2페이지 검색 결과 알려줘"와 같이 요청하면, Cursor AI는 등록된 MCP 서버의 search_blog Tool을 page=2 파라미터와 함께 호출하고, 서버로부터 받은 결과와 동적 Prompt를 반영하여 사용자에게 응답을 제공합니다.

5.2 Claude Desktop 연동 설정
Anthropic의 Claude AI를 사용하는 Claude Desktop 애플리케이션 역시 MCP 서버 연동을 지원합니다.
Claude Desktop 설치 및 실행
공식 배포처를 통해 Claude Desktop을 설치하고 실행합니다.
MCP 서버 등록
server.py 파일이 위치한 프로젝트 디렉터리(py-mcp-naver-search)에서 터미널을 엽니다. 반드시 가상 환경이 활성화된 상태여야 합니다. 다음 명령을 실행하여 현재 프로젝트의 MCP 서버를 Claude Desktop에 등록합니다. 저장되는 경로는 ~/Library/Application\ Support/Claude/claude_desktop_config.json입니다.
mcp install server.py
설정 파일 확인
설정 파일을 열어보면 방금 명령어로 실행한 MCP 서버 정보를 추가되어 있을 것입니다. 다만, 그대로 사용하면 오류가 발생할 수 있으니 변경 후 코드로 적용해 주세요.
command에는 uv 명령어의 절대 경로로 변경합니다. directory에는 py-mcp-naver-search 프로젝트의 절대 경로로 변경합니다.
# 변경전
{
"mcpServers": {
"Naver Search MCP Server": {
"command": "uv",
"args": [
"run",
"--with",
"mcp[cli]",
"mcp",
"run", "/Users/jikime/src/cookai.dev/oh-my-agent/mcp-servers/py-mcp-naver-search/server.py"
]
}
}
}
# 변경후
{
"mcpServers": {
"Naver Search": {
"command": "/Users/jikime/.local/bin/uv",
"args": [
"--directory",
"/Users/jikime/src/cookai.dev/oh-my-agent/mcp-servers/py-mcp-naver-search",
"run",
"server.py"
]
}
}
}
Claude Desktop 재시작 및 활성화
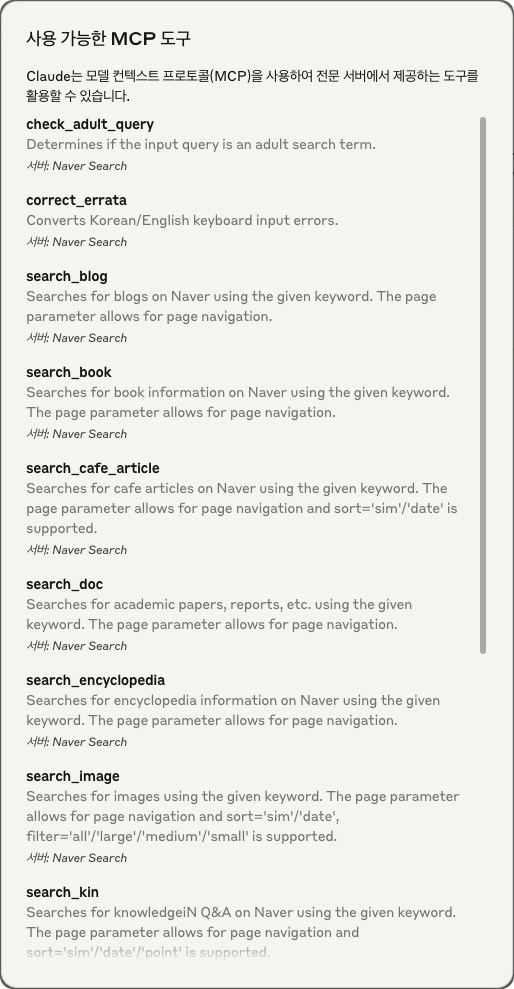
Claude Desktop 애플리케이션을 완전히 종료했다가 다시 시작합니다. 정상적으로 실행되면, 서버는 JSON-RPC 요청을 수신할 준비가 됩니다. 그리고 아래 이미지처럼 도구모양의 아이콘이 생기고 클릭 시 13개의 도구 목록을 확인할 수 있습니다.

MCP 서버와의 연결 테스트
Claude Desktop이 MCP 서버와 제대로 연결되었는지 확인하려면, 도구 호출을 테스트합니다.
도구 요청
대화 창에 도구와 관련된 질문을 입력합니다. 예를 들어,
AI와 관련된 책 1권을 찾아줘.
Claude는 내부적으로 MCP 서버의 도구(예: search_book)를 호출하여 결과를 가져옵니다.


권한 요청 확인
- MCP 서버의 도구를 처음 호출할 때, Claude Desktop은 사용자에게 도구 사용 허가를 요청하는 팝업을 표시합니다.
- 허가를 승인하면 도구가 실행됩니다.

이제 Claude와의 대화 중에 네이버 검색 관련 질문이나 요청을 하면, Claude는 등록된 MCP 서버의 Tool을 활용하여 답변을 생성할 수 있습니다. 서버에서 반환하는 동적 Prompt 정보는 Claude의 응답 스타일에 영향을 줄 수 있습니다.
제6장: 결론
이 글을 통해 네이버 검색 Open API를 활용하는 MCP 서버를 Python으로 구축하고, 동적 Prompt 생성, 페이지네이션, 로깅 및 오류 처리 강화, 코드 리팩토링 등 기능을 적용하는 과정을 상세히 살펴보았습니다. uv를 사용한 효율적인 프로젝트 설정,. env를 통한 안전한 키 관리 방법을 포함하여 AI 어시스턴트의 정보 접근 능력을 크게 향상하는 실질적인 방법을 학습했습니다.
이제 개발자는 보다 정교하고 안정적인 MCP 서버를 개발하고 AI 애플리케이션에 통합할 수 있는 기반을 갖추었습니다. 제시된 코드를 기반으로 다양한 아이디어를 접목하여 더욱 강력하고 사용자 친화적인 AI 에이전트를 개발해 보시기 바랍니다. MCP는 AI 모델의 능력을 확장하고 특정 도메인 지식이나 실시간 정보 접근성을 높이는 데 효과적인 도구가 될 것입니다.
'Cook AI' 카테고리의 다른 글
| 코딩의 첫걸음: 도구와 프로젝트 구성 (5) | 2025.05.05 |
|---|---|
| 커서의 챗 기능: AI로 혁신하는 코드 편집과 관리 (3) | 2025.05.04 |
| AI를 활용하여 유튜브 쇼츠를 제작하는 방법 (2) | 2025.04.23 |
| Cursor AI - 규칙 생성 및 에이전트 터미널, MCP 이미지 개선 (1) | 2025.04.22 |
| MCP 도구 요청 플로우 (0) | 2025.04.16 |